Introduction
Apple is making machine learning available to everyone. With the latest advancements in CoreML 3 and the new CreateML app, it’s very easy to make your apps smarter. In this post, we will build an app that will detect music instruments in songs.
The songs used in the video are U2 – Sometimes you can’t make it on your own, Pink Floyd – Comfortably numb and Coldplay – Christmas Lights. Feel free to try it with different ones and provide a feedback.
Create ML app
CreateML was announced last year, as a Swift tool that helps in the creation of machine learning models. Until this year, you would have to make the models in playground, by writing Swift code. However, this year, there’s a new CreateML app, shipping with Xcode 11 (you need to have macOS Catalina to be able to use it). It’s available in Xcode -> Open Developer Tool -> Create ML.
To get started with Create ML, create a new project. There are several templates available to get started, such as image classification, object detection, text classifications, sound classification, etc.
Obviously, we will need the sound classifier. Choose that one and provide a name for the project. Mine was called the default MySoundClassifier.
The training data
With Create ML, you don’t have to bother with writing or even selecting machine learning algorithms. Create ML does that for you. That means, the biggest challenge in this classification is collecting the data for training and testing.
There are several data sets available for classifying music instruments. After several large downloads and failed attempts, the one that worked for me was the IRMAS dataset. If you want to follow along, you will need to download the training set and the three testing sets.
The training dataset consists of 11 different classes of instruments. This means, if another instrument (which is not in these 11) appears in a song, it will be wrongly classified as one of the existing ones. All the folders contain .wav audio files, which contain examples of that particular instrument.
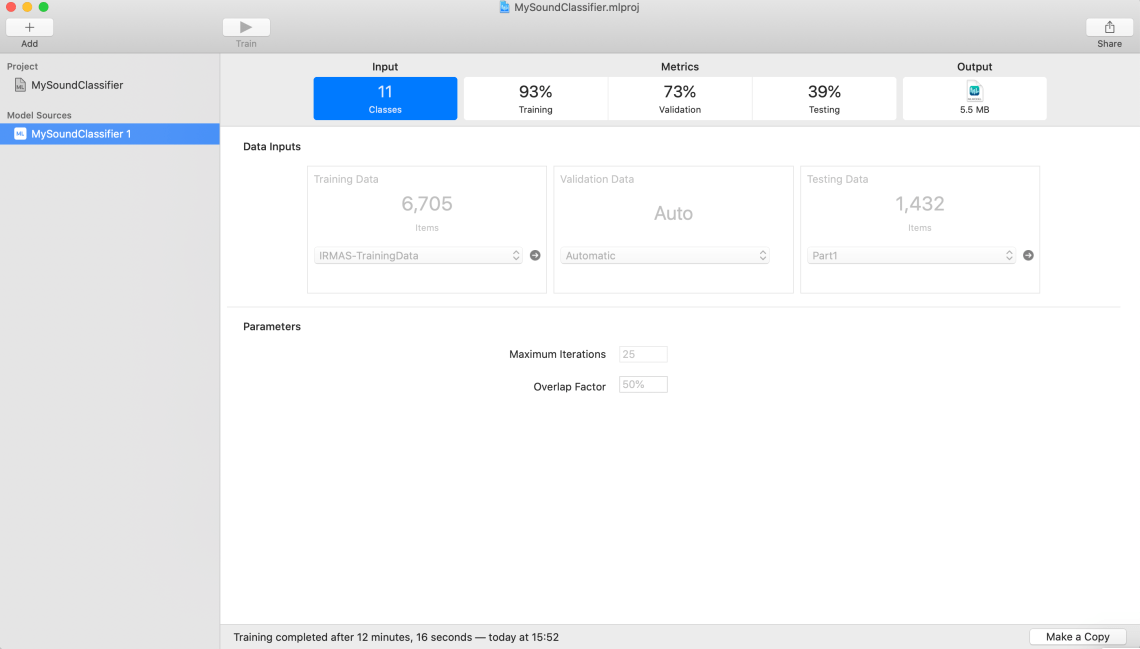
In the Data Inputs section, under Training Data, add the training folder from above. For validation data, leave it automatic.
By pressing play, you can start the training of the model. For me, it finished for around 12 minutes.
Let’s go through the detected metrics. First, Create ML correctly detected that there are 11 classes for this sound classification problem. Next, we have training and validation accuracy. For me, this is 93% and 73% respectively.
Create ML doesn’t use all images for training, it leaves some small percentage of the data to check how good is the model. It doesn’t train the classifier on these images – those are used for evaluation only. So of those not used for training, 73% were classified as correct and that’s the validation accuracy. You can play with the number of iterations to get different values for validation accuracy.
The testing data
At this point, the model is created, so we need to test it. I’ve mentioned above that you would need to download additional testing dataset, which is in a slightly different format then the testing data. It’s in three different parts, which contain both txt and wav files. The txt files contain information for the class where the sound is classified.
What we need to do is convert this data in folders per class, just like the training set. In order to do this, we will write a Ruby script.
require 'fileutils'
parts.each do |part|
Dir.entries(part).select { |f|
if File.extname(f) == ".txt"
basename = File.basename(f, ".txt")
filePath = "#{part}/#{f}"
File.readlines(filePath).each do |line|
testDir = "test"
Dir.mkdir(testDir) unless File.exists?(testDir)
directoryPath = "#{testDir}/#{line}".strip!
Dir.mkdir(directoryPath) unless File.exists?(directoryPath)
audioFile = "#{part}/#{basename}.wav"
FileUtils.cp(audioFile, directoryPath)
end
end
}
end
Go to your terminal and run the script (let’s call it organize.rb) at the root folder where the three subfolders with testing data are located: ruby organize.rb.
If it’s successful, you will see a new folder called test, with eleven sub-folders for the classes for testing. Add those in the testing are in Create ML. For me, the accuracy was around 40%, which is far from ideal, but it’s a good starting point.
Integrating into an iOS project
You can easily export the Core ML model by dragging it out of Create ML and dropping it into an iOS project.
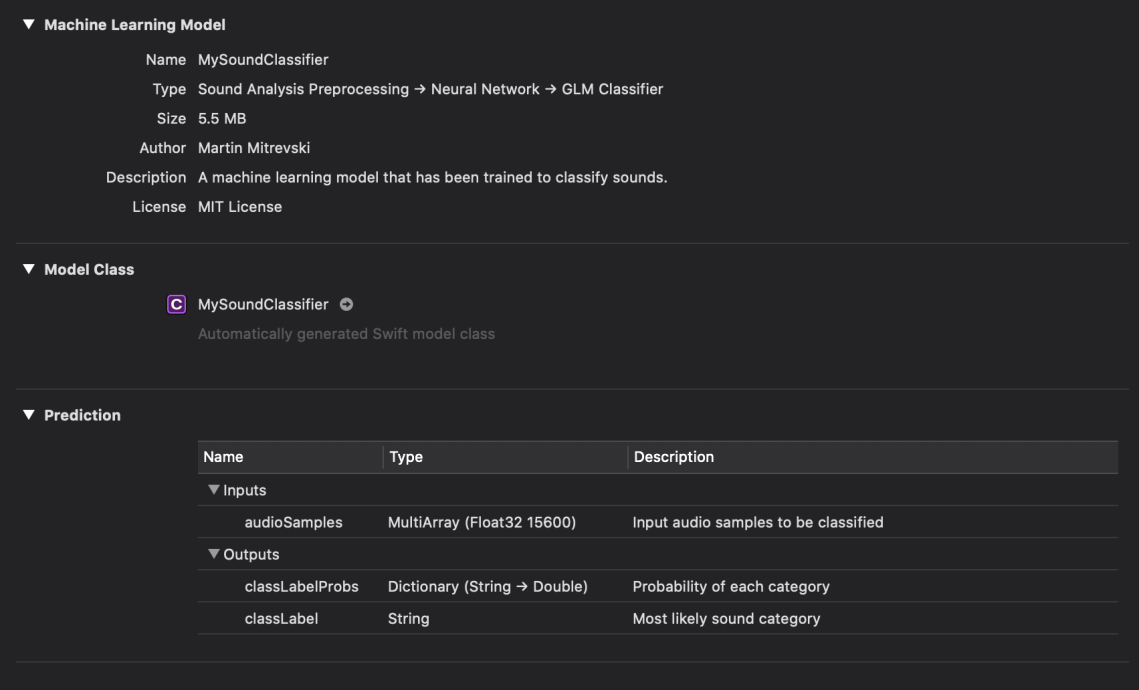
Let’s examine the contents of the generated model. As you can see, its type is sound analysis preprocessing, then neural network and after that GLM classifier. Create ML figured all these things out by itself, we haven’t specified anything. Its size is pretty small, around 5.5 MB, although the training and testing data was over 10 GB.
The input for this model is multi-dimensional array of audio samples and the output is a dictionary of probabilities and a class label.
But how are we going to transform the data from the user recording to this multi-dimensional array?
SoundAnalysis
Luckily, Apple takes care of that as well. SoundAnalysis is a new framework from iOS 13, which takes the audio stream and uses it in a classification request for Core ML. It does all the necessary transformation to use it in a Core ML prediction.
But first, we need to setup the audio engine. For more details what we do here, please refer to my other post about voice responsive AR apps.
private func startAudioEngine() {
audioEngine.prepare()
do {
try audioEngine.start()
} catch {
showAudioError()
}
}
private func prepareForRecording() {
let inputNode = audioEngine.inputNode
let recordingFormat = inputNode.outputFormat(forBus: 0)
streamAnalyzer = SNAudioStreamAnalyzer(format: recordingFormat)
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) {
[unowned self] (buffer, when) in
self.queue.async {
self.streamAnalyzer.analyze(buffer,
atAudioFramePosition: when.sampleTime)
}
}
startAudioEngine()
}
The new thing is the streamAnalyzer, which does the required transformations of the sound to be able to use it with Core ML.
When the user starts the recording button, we need to create the classification request and give as input the things that the analyzer above converted for us.
private func createClassificationRequest() {
do {
let request = try SNClassifySoundRequest(mlModel: soundClassifier.model)
try streamAnalyzer.add(request, withObserver: self)
} catch {
fatalError("error adding the classification request")
}
}
How do we handle the results? As you can see above, we are setting ourselves
(the ViewController in this case), to be observer of the stream analyzer. This means we would have to implement a protocol – SNResultsObserving.
extension ViewController: SNResultsObserving {
func request(_ request: SNRequest, didProduce result: SNResult) {
guard let result = result as? SNClassificationResult else { return }
var temp = [(label: String, confidence: Float)]()
let sorted = result.classifications.sorted { (first, second) -> Bool in
return first.confidence > second.confidence
}
for classification in sorted {
let confidence = classification.confidence * 100
if confidence > 5 {
temp.append((label: classification.identifier, confidence: Float(confidence)))
}
}
results = temp
}
}
The delegate method returns as SNClassificationResult, each time something is classified. This is called many times per second. What we are doing is that we first sort the results, filter them and transform them in order to be presented into a table view.
Conclusion
Those are the main things relevant for sound classification. You can find the full source code here.
To sum up, adding machine learning is easier with Create ML and its many templates for several ML problems. The classification results are ok, but there’s a lot of room for improvement. First, more instruments need to be added, because now if something is not recognized, it’s classified wrongly.
What are your thoughts on this? Have you tried sound classification already? Do you find any interesting use-cases for it? Write your thoughts and comments in the section below.

Thanks, this made me start learning “Sound processing ML” related concepts.
A slight change applicable to the ruby script: The variable “parts” needs to be declared with the sub-folders name (as relevant).
LikeLike