Introduction
Augmented Reality and Conversational Interfaces are two of the hottest technologies at the moment. They both bring a broad range of opportunities to make cool and innovative apps. The question is, what happens if we combine these two emerging technologies? The answer – we get one really smart pony.
Implementation
To make this lovely pony respond to our commands, we will be using Apple’s Speech framework, SceneKit and ARKit. We will use ARKit for scene tracking and placing virtual objects in the physical environment. SceneKit will be used for rendering the virtual objects, as well as for controlling the animations of the pony. Speech framework will be used to translate our voice commands to a machine readable text. We will use that text to perform the appropriate action – either load the animal or animate it.
Placing virtual objects on horizontal planes is something already done many times in many posts. In order not to re-invent the wheel, we will start with Apple’s sample project for this and modify it to suit our needs. This project contains best practices for visual feedback, gesture interactions, and realistic rendering in AR experiences.
What we need to do is to complement the button for adding 3D models with a voice action, as well as support voice controlled animations on that object.
Adding voice capabilities
First, let’s start with the speech part. For this, we will extend the UI of the AR view with additional recording button. When this button is clicked, the recording and the speech recognition start. The results of the user’s queries are displayed on a label below the recording and add buttons.

Speech framework
To handle the speech related functionalities, we will create an extension of the main ViewController in the project, called ViewController+Speech. The first thing we need to do is check whether the user has granted us the permissions we need to access the speech recognising feature. If that’s not the case, we will show an alert dialog.

Next, let’s see what happens when the recording button is pressed.

In order to understand this method and it’s two states, we will introduce few new types of objects. We will start with the audioEngine variable. It’s an object from the class AVAudioEngine, which contains a group of nodes (AVAudioNodes). These nodes perform the job of audio signal creation, processing and I/O tasks. Without those nodes, the engine wouldn’t be able to do its job, but also AVAudioNodes do not currently provide useful functionality until attached to an engine. You can create your own AVAudioNodes, and attach them to the engine, using the attach(_ node: AVAudioNode) method.
Let’s introduce another new object, recognitionRequest, of the class SFSpeechAudioBufferRecognitionRequest. This class is used for requests that recognize live audio or in-memory content, which is what we need in this case. We want to show and update the transcribed text when the user says something.
The third object that we will introduce is recognitionTask (SFSpeechRecognitionTask). With this task, you can monitor the recognition process. The task can be either starting, running, finishing, cancelling or completed. This kind of object is what we get when we ask the speech recognizer to start listening to the user input and get back to us what it heard. The speech recognizer is represented by the SFSpeechRecognizer class and this is the class that does the actual speech recognizing.
Now let’s see how we can put all these different objects together to start the recording of the user.

There are a lot of things going on here, but as you will see, it’s not that complicated. First, we start the recognition task for the speech recognizer, with the recognition request we’ve talked about above. When there’s a result in the resultHandler of the speech recognition task, we are getting the best transcription by calling the result?.bestTranscription.formattedString. If you want to show a popup with other transcriptions and let the user choose the one that fits best, you can call the result?.transcriptions which will give you an array of the possible transcriptions.
Every SFTranscription object contains two properties – formattedString and segments (SFTranscriptionSegment). Segments contain other information that you might find helpful, like confidence (on a scale of 0 to 1), which gives you an indication how accurate is the Speech framework that this string is the one the user has spoken. This property is used when figuring out which transcription is bestTranscription.
We would like to write and update the transcription as the user gives voice commands. That’s why we are setting the recognized text to our text view (self.recognizedText.text = recognized). Then we are checking whether the recording finished (finishedRecording = result!.isFinal). If it did, we are removing the audio tap from the input node’s bus, that we have added at the beginning, nil out the request and the task and stop the audio engine.
Now let’s go back to the cancelCalled flag. It is used to stop subsequent calls to the method that updates everything when the recording state changes (handleRecordingStateChange). The subsequent calls can happen because the result handler is called on every sound that’s recognized – which means it can be called even after the triggering stop word is found.
In the handleRecordingStateChange method’s other state (when the audioEngine is already running), we stop the recording with all the relevant objects (the speech recogniser, the audio session, recognition request). This is also the place where we need to check whether the user input contains something we can handle.
Keyword recognition
To understand what the users say is pretty complicated task. You can use a conversational interfaces platform like Dialogflow or Wit.ai (more details about these topics in my book Developing Conversational Interfaces for iOS). In order not to make this post as big as a book, we will use a simpler approach – keywords recognition.
What this means is that if a predefined word appears in the user’s input, that word will trigger an action. In our case, examples of keywords would be “pony”, “jump”, “sit”, “yes”, “crazy”.
Since we want to leave space for a more advanced implementation later one, we will create a protocol called SpeechService, that will convert String to a SpeechAction. Actions can be of two types, addAnimal and animateAnimal.

The KeywordsSpeechService implementation splits the text into words and then tries to create an enumeration for the supported animal and animation types. If it does, it returns a SpeechAction with the particular type.

The supported animal types are dog and pony and they can jump, sit, lay or say yes.
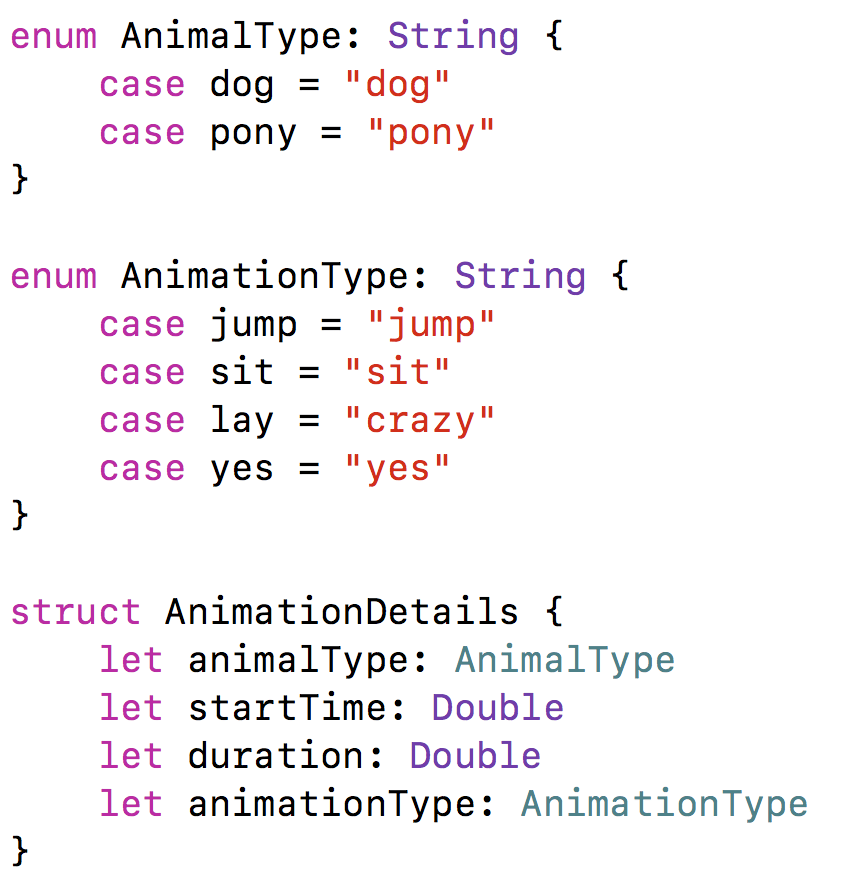
Performing the animations
The struct AnimationDetails is used to perform animation on the 3D model. It contains information about the animal, the animation type, as well as the start time and duration of the animation. The 3D models used in this app already have the animations at particular start times and duration. This information is manually extracted in a JSON file, which is populating the AnimationDetails structs.

In order to start the recognised custom animation, we need an AnimationManager with the following method.

What we are doing here is first crop the animation we need from the 3D model. For this, we are using the animation details defined above. Next, we are creating SCNAnimationPlayer, which is then added to the virtual object. Next, the player is started and the animation is previewed.
To crop the animation, we are creating a copy of the full animation, where we are setting the time offset and the duration of the animation of interest.

These are the main things that we needed to make this smart pony answer to our questions and commands.

Source code
You can find the full source code of the implementation here. Have in mind that the git repo doesn’t include the models, since they are commercially purchased. You can include your own 3D models and actions. Don’t forget to edit the animals.json file for this.
Conclusion
This is one example of how different technologies can be blended together in order to open up new possibilities for creating innovative products. Enabling conversational interfaces in AR apps is even more interesting for headsets, because there is still no easy enough interface in those devices. It is a nice addition to the eye-gazing and finger gestures already used in the headsets.
What are your thoughts on the intersection of Augmented Reality and Conversational Interfaces? Do you think they open up new possibilities for building cool apps? Share your thoughts in the comments section.
Huge thanks to Vilijan Monev for making a valuable contribution to this post.

Exactly the help and example I was looking for. Thank you!! Also found and bought your book Developing Conversational Interfaces for IOS at Apress. Look forward to studying this example and reading your book.
LikeLike
Thanks, glad I could help! Hope you will enjoy the book. Cheers
LikeLike